{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

 Go to contents Go to Salford home page
Go to contents Go to Salford home page
Discussion of ASN.1 is included at this point in the text as the notation is effectively part of the interface between the application layer and the presentation layer. It is a definitional notation used by application designers which invokes algorithms (encoding rules) that are effectively part of the presentation layer.
The text cannot hope in the space available for ASN.1 discussions to provide a complete tutorial on the use of the notation, and the reader is referred to other texts or to the Standard if serious work is to be done using ASN.1, either as a reader of published specifications, or as an application designer using ASN.1. The aim here is to present the major features and principles of ASN.1 and its encoding rules, with some discussion of conceptually difficult areas and remaining problems and issues (as at the start of 1992).
In the second part of this Chapter, there is discussion of new work related to ASN.1. This discussion is based on the Draft International Standard text, and whilst it is hoped that much of what is presented will remain valid, the reader is cautioned to check later text as it emerges from the standardization process.
The idea of providing support for application designers by providing a notation for defining data structures, a defined (machine-independent) encoding for those data structures, and tools to produce such encodings from local representations of data in programming languages was an important one, and is normally credited to the Xerox Courier Specification, part of the XNS protocol suite.
In early 1980 there was recognition within the CCITT group that defining the X.400 (electronic mail) protocol would involve some very complicated data structures, and that notational support for this activity was essential. A language was needed with about the power of normal high level programming languages for defining repetitive and optional structures using a number of primitive data types. But it needed to be supported by an algorithm (later called encoding rules) which would determine the bit-pattern representation during transfer for any data structure (no matter how large or complex) that could be written down using the language. The Xerox Courier Specification provided important input, and the notation was developed into CCITT Recommendation X.409 - part of the X.400(1984) series.
At that time, most groups developing Application Layer standards in ISO had identified a similar problem: the protocols they were developing were just getting too complicated for hand-crafting the bit-patterns. Here, however, the problem was exacerbated by the strong emergence of the Presentation Layer concept of separating abstract and transfer syntax definition (these concepts were accepted much later by CCITT/ITU-T workers), which required some sort of notation to glue together the two definitions. No such notation was emerging. Some groups tried using variants of BNF (Backus-Naur Form), a notation originally developed to help programming language designers to precisely specify the syntax of their programming languages. It had the necessary power, but there was no de facto standardization of the notation, and of course no agreed and application-independent encoding rule specification.
When drafts of X.409 were passed to ISO, they were greeted with open arms, and the acceptance of this notation as the way to define OSI Application Layer protocols was almost (and unusually) immediate and universal. The text did, however, undergo an important change. X.409 was written as a single specification, with a series of paragraphs each of which first presented a language construct, then presented the algorithm defining the encodings related to that language construct. For ISO purposes, with the concept of a clear separation of transfer syntax definition (with potentially multiple transfer syntaxes for any given abstract syntax), these two aspects needed to be clearly separated in separate documents. X.409 was therefore re-written as ISO 8824 and ISO 8825.
ISO 8824 was called Abstract Syntax Notation One (reflecting recognition that there could well be other notations for abstract syntax definition), and ISO 8825 was called Basic Encoding Rules (reflecting recognition that other encoding rules could indeed exist). At this time the abbreviation for the notation was ASN1. But it was amazing how often it got mistyped as ANS1 and then misread as ANSI - the abbreviation for the American National Standards Institute! The Americans said "Look, we know it is not the same abbreviation, and confusion should not occur, but in fact we are getting confusion. Would it be possible to find another name?" The resolution of the discussion was the introduction of the "dot" into the abbreviation, so we now have "ASN.1", and nobody ever mistypes it as ANSI! (ANS.1 is the nearest you get.) The abbreviation for the encoding rules was BER, which provided no problems.
There was, of course, some reluctance on the part of CCITT to adopt completely new text from ISO because of fears that technical changes might have been introduced, but in the end (about 1985/86) CCITT agreed to work with common text based on the ISO drafts, and eventually published such text in the 1988 Recommendations as X.208 (ASN.1) and X.209 (BER), withdrawing X.409. The move into the X.200 series - general OSI infrastructure - reflected the (universal) view that ASN.1 was nothing to do with X.400 as such, but was a general tool for all OSI application designers to use.
A number of additions were made to ASN.1 during the 1980s, the most important of which was the OBJECT IDENTIFIER data type used to carry the names of abstract and transfer syntaxes (and many other types of conceptual object needing names in OSI), but there were no major additions to the concepts introduced in X.409. By contrast, a significant number of new concepts were introduced into the work nearing completion in 1992, and discussed in the next section.
Readers who are already largely familiar with ASN.1 should skip this section - it is about the "What?" and not the "Why?" - but it would be wrong not to include at least this overview for readers who have never met ASN.1 before.
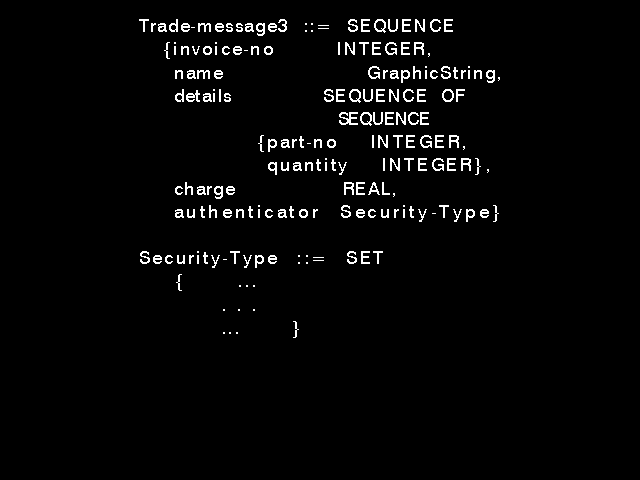
The best way to understand any language or notation is to read a few examples of it, and these are readily obtainable from any of the OSI application layer standards. figure 8.1: An ASN.1 datatype definition and figure 8.2: An ASN.1 datatype definition (bis) are often-quoted examples originally developed by this author. They are fictitious, designed only to illustrate features.
The first point to note is that an ASN.1 datatype is built-up from primitive data types (INTEGER, REAL, BOOLEAN, NULL) using three main construction mechanisms: repetition (SEQUENCE OF and SET OF), alternatives (CHOICE), and lists of fields (SEQUENCE and SET). Once an ASN.1 data type has been defined, it can be used in the definition of other ASN.1 data types exactly as if it were a primitive data type, and such types can be defined before use or after (forward references). Indeed, mutually recursive data structures are permitted. Combined with CHOICE, such recursively-defined data structures can still have finite representations for some of their values. In the figure 8.1, Name, Sector, Country, and Product-line are the names of data types defined before or after the definition presented in the figure. Equally, the definition of these data types could have been included in-line in the definitions in the figure.
The second point to note is that for the SEQUENCE construction, each field is listed (separated by commas) as a field-name (beginning with a lower-case letter - ASN.1 is case sensitive) which plays no part in defining the actual bits on the line followed by the name of a primitive type or defined data structure which determines the form of the field.
A complete list of the ASN.1 primitive types in the version of ISO 8824 dated 1990 is given in figure 8.3: ASN.1 primitive types (1990).
There are a small number of points to make here to help the reader understand the ASN.1 in the figures or in standards. More substantive points are addressed in the next part of this Chapter.
The NULL datatype is typically used in a CHOICE to identify an element where all that matters is that that particular CHOICE is occurring, with no additional information to be provided or needed. The text in square braces (for example "[0]" in the figure) is called a tag and is discussed more fully below.
ASN.1 has the concept of a module within which definitions can be grouped, from which they can be exported, and into which they can be imported. Modules are identified by an ASN.1 OBJECT IDENTIFIER value (although early definitions did not contain these), and strictly speaking anyone who wants to use ASN.1 needs a part of the object identifier name space - see later discussion. If one looks at the connectivity of modules obtained by export and import links, it includes almost all the ASN.1 modules defined in any Application Layer standard - there is use in almost every standard of some importation or exportation of ASN.1 definitions from/to some other standard.
The difference between SEQUENCE and SET is in the order of transmission of the fields: for SEQUENCE, a sender is required to transmit them in the order listed in the notation; for SET, the order of transmission is an implementation option for the sender. This could, of course, be regarded as an encoding issue that the application designer should not be concerned with, and which has no place in the notation. Indeed, in order to provide canonical encodings (encodings with no options), this freedom is removed in some encoding rules and SET then becomes synonymous with SEQUENCE.
INTEGER fields in ASN.1 are not constrained to 16 bit or 32 bit integers. Rather, they are indefinitely large. An important addition round about 1988 was the introduction of a subtype notation, most commonly used to sub-type integers, but applicable to any ASN.1 type. This notation in its full glory is quite complex, and enables a new type to be defined as any subset of the values of any given type. The notation is enclosed in round brackets, and is most commonly used in the following way:
Month ::= INTEGER (1..12)
Day ::= INTEGER (1..31)
Daily-temperatures ::= SEQUENCE SIZE (31) OF INTEGER
Name ::= PrintableString (SIZE (1..20 ))
The fields in a SEQUENCE or SET can be marked OPTIONAL, in which case they may be present or absent in a message (the application designer then needs to state what it means if they are absent). (ASN.1 uses the term element rather than "field".) Alternatively, they can be marked DEFAULT, followed by a value for the datatype of the element. For example, "INTEGER DEFAULT 3". This states that if the element is missing, the meaning is exactly the same as if it were present with the value 3, and the application designer need add no further text. It is important to recognise here that ASN.1 allows default values not just for primitive fields like INTEGER and BOOLEAN, but also for any arbitrarily complicated data type that can be defined using ASN.1. In this it goes further than most typical programming languages. Equally, just as complicated types can either be written down within an enclosing definition or be defined separately and referenced, so complicated values can be written down after the DEFAULT keyword or can be defined separately and referenced.
The value notation was originally designed specifically to support the DEFAULT keyword, but it has found applications within the English text of application standards to identify special cases, in tutorials to identify values being transmitted, in the notation for defining subtypes of a type, and latterly in the newly introduced information object concept (see below). In the case of OBJECT IDENTIFIERS, there are many, many more instances of the value notation (to assign object identifier values to modules, abstract syntaxes, transfer syntaxes, and so on) than there are instances of use of the words OBJECT IDENTIFIER for type definition. As with the type notation, the value notation is fairly obvious and easily understood. Further discussion here is not appropriate.
Provision in the notation for a data type to carry unambiguous identification of objects (the OBJECT IDENTIFIER data type) would not be very useful unless enough additional text was produced to determine how values of this type got assigned to objects that needed identifying, and how such values could be encoded. This led the ASN.1 group into the definition of a structure of registration authorities to support this need and hence (arguably) into activity that went outside of the group's defined scope - that of defining a notation for data structure definition.
(The reader may be unfamiliar with many of the objects and standards mentioned in this paragraph. They are here for illustration and no attempt is made to describe them in detail. In some cases they will be discussed further later in the text.) There are a number of mechanisms in use in OSI and related standards for unambiguous naming of objects, with a variety of properties and requiring a variety of organizational structures (registration authorities) for the allocation of parts of the name space. There have been some discussions about trying to rationalise the provision of naming formats in OSI to some minimum necessary number, but this has not come to fruition. Thus communications-related standards such as SGML (Standard Generalized Mark-up Language) and EDIFACT (Electronic Data Interchange for Finance, Administration, Commerce, and Transport) and CDIF (CASE Data Interchange Format) all define their own naming structures with properties very similar to ASN.1 object identifiers. There are also separate naming and addressing structures used for X.500 Distinguished Names, X.400 Originator/Recipient Names, and Network Service Access Point addresses. Nonetheless, the range of objects for which ASN.1 object identifiers have been specified as the naming mechanism is large: abstract and transfer syntaxes, ASN.1 modules, Application Contexts, Application Entity Titles, ROSE Operations, X.500 attributes (the component parts of X.500 Distinguished Names), X.400 Extended Body Parts, FTAM Document Types and Constraint Sets, Terminal Profiles, RPC Interface types, and Managed Objects and their attributes.
The ASN.1 object identifier name-space was built on similar principles to the name-space used for allocating Network Service Access Point (NSAP) addresses, but with the important distinction that NSAP addresses had of necessity to have a (relatively) short maximum length whilst ASN.1 object identifier values are normally carried in application layer protocols where length is not too much of an issue and indefinite length can be accepted. Nonetheless, common to both is the principle of a world-wide unambiguous name designed so that almost anybody could relatively easily obtain a part of the name-space for allocation to objects that they wished to identify. (The reader might care to consider at the end of this section how he personally - in his business capacity - might most easily obtain a part of the object identifier name space for his own part of his organization's use.)
Another important issue which arose in the definition of the ASN.1 object identifier was whether the identifiers should be relatively terse and numeric (efficient in transfer), but relatively unfriendly for human use, or whether they should contain character parts (or be exclusively character-oriented, making them more verbose but more human friendly).
The decision for ASN.1 names was to make them terse and numeric, whilst the later decision for X.500 Distinguished Names was to provide for a much greater use of character information. In fact, X.500 names consist of a series of attributes, each attribute having a value (typically, but not necessarily, a character string). A value of the name during transfer is defined as the value of an ASN.1 data structure which is a sequence of items, each item in the sequence itself being a pair of items, the first of which is an ASN.1 object identifier that identifies a defined attribute, and the second of which is the value of an ASN.1 type determined when the attribute was defined.
At the same time as the decision was taken to introduce the OBJECT IDENTIFIER data type to carry world-wide unambiguous terse names, the OBJECT DESCRIPTOR datatype was introduced to carry a user-friendly name that would be likely to be world-wide unambiguous, but was not guaranteed so to be. In fact, it was simply a character string, with no allocation of name-space, and no restrictions (other than the application of common sense) on the strings that are allocated by different groups. The idea was that whenever an object identifier value was allocated to identify an object unambiguously, an object descriptor value would be allocated at the same time to provide user friendly but not necessarily unambiguous identification. A protocol designer providing fields to identify objects would typically provide a field of type OBJECT IDENTIFIER, but would then choose whether to accompany this with a field of type OBJECT DESCRIPTOR, either mandatorily present or present at the option of the sender (use of the keyword OPTIONAL). What has happened in practice is that application designers have chosen with almost no exceptions to provide only a field for carrying the OBJECT IDENTIFIER, and one often finds allocations of object identifier values to defined objects with no corresponding object descriptor value allocated. Thus object descriptors can be regarded largely as a historical relic.
What then does the OBJECT IDENTIFIER name space look like? It is based on an object identifier tree which is a structure with a root node, arcs beneath that to other nodes, with arcs beneath them, and so on. Each node is assigned to some responsible body that allocates arcs and nodes beneath it. The body ensures that all the arcs beneath its node are numbered sequentially starting from zero (names - lower case - can also optionally be assigned to an arc), and that each node beneath it is either assigned to some responsible body (or retained for further use by the body itself) or is assigned to name some information object. "Information object" is the term used for things that are named by object identifiers, and reflects the fact that usually (but not always) the "thing" being named is some definition or piece of information, such as an abstract syntax definition. Thus information objects being named by object identifiers are all associated with some leaf node of the tree. The object identifier name of an information object is a list of integer values which are the values of the arcs, taken in order, from the root of the tree to the leaf node assigned to name the information object. Thus a typical object identifier could be written as
{1 0 8571 2 1}
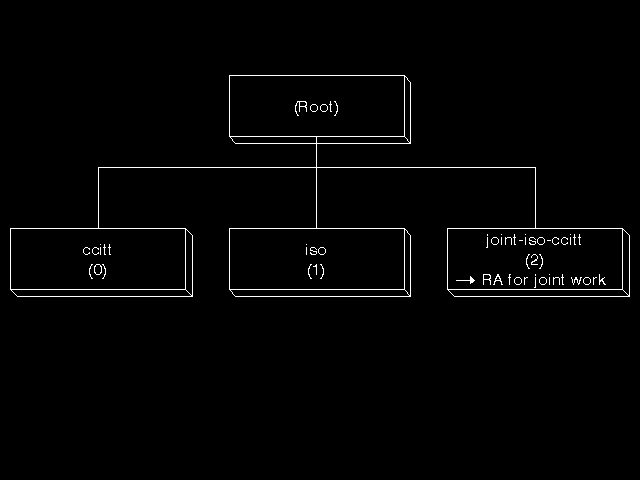
and is encoded for transfer as specified in the ASN.1 Encoding Rules. The top parts of the tree are allocated and assigned numbers and names within the ASN.1 Standard. (See figures 8.4: Top arcs of object identifier tree, 8.5: The CCITT/ITU-T branch of the tree, and 8.6: The ISO branch of the tree). In computer communications, the names of arcs play no part, but in writing down object identifier values for human consumption it is permitted and normal to use the names instead of the numbers for those arcs allocated in the ASN.1 Standard. For other arcs, either just the number is given, or the name is given with the number in brackets. Thus the above example would more usually be written as:
{iso standard 8571 abstract-syntaxes(2) ftam-pci(1)}
being an object identifier allocated in the FTAM Standard (ISO 8571) to name the abstract syntax of their main protocol messages.
Figure 8.4 shows the top three arcs, assigned for CCITT/ITU-T use, ISO use, and allocation by joint ISO and CCITT/ITU-T decision. Beneath the "joint" arc, we have about twenty arcs allocated so far for areas of joint ISO and CCITT/ITU-T standardization. Thus all object identifiers used in the X.400 series of Recommendations begin
{joint-iso-ccitt mhs-motis(6) ......}
Note the problems that this use of "ccitt" causes when the name of CCITT was changed to ITU-T. (At the time of writing, the top arc is still labelled "joint-iso-ccitt", but the text says that the responsibility for further allocation lies with ITU-T.)
Figure 8.5 shows the arcs beneath the ccitt arc, providing some name space for the writers of CCITT/ITU-T Recommendations (where the work is not joint with ISO), to PTTs, and to RPOAs (private telephone operators). The Recommendation arc has twenty six arcs beneath it, numbered 1 to 26, and corresponding to the letters A to Z. Beneath each of these there is an arc for every CCITT/ITU-T Recommendation, numbered with the number of the Recommendation. Thus, should they require it, the writers of Recommendation G.432 could allocate object identifiers beginning
{ccitt recommendation g(7) 432 .....}
Figure 8.6 shows the arcs beneath the ISO arc, providing in a similar way name-space for the writers of ISO standards (where the work is not joint with CCITT/ITU-T). There are also (importantly) two further arcs, one giving name-space to National Bodies (such as BSI in the UK and ANSI in the USA) using the Standard ISO 3166 that allocates three digit numeric codes to countries, and one giving name-space through an existing ISO registration authority which will allocate to international organizations an International Code Designator (ICD), a four digit numeric code. In the case of the UK, BSI has set up mechanisms for the allocation of object identifiers to anybody in the UK needing some name-space, beneath the national-body arc. ECMA has obtained an International Code Designator and is prepared to allocate beneath that to its members. At least two major computer vendors are known to have obtained their own ICD. Rather interestingly, the US Government chose not to allocate under National-Body, but rather sought and obtained a pair of ICDs, one for civil and one for military use, and is allocating under those.
In general then, it should be relatively easy for any organization within the UK and the USA to get some object identifier name space. In other countries similar developments are occurring at varying paces.
Nonetheless, there still remains some concern that getting object identifier name space to the lowest levels may prove difficult. Thus in theory, if a lowly computer bureau user made use of the Distributed Transaction Processing (DTP or TP) protocol through an operating system interface to COBOL programs that he wrote to communicate between two machines, he would need some object identifier space to identify the resulting syntaxes and procedures that he was employing: he has, in fact, defined a protocol. There was, and still is, concern that this could inhibit the use of the TP Standard, and text has been included in these Standards to provide object identifiers sufficient for use in these circumstances.
Rather more discussion of the Basic Encoding Rules in general occurs below, but here we mention briefly the encoding of the REAL datatype. (Readers who have never undertaken assembler language programming and are unfamiliar with floating point number formats in computer hardware may want to skip this section.) The following discussion gives the "Why?" of the representation of REAL, and the reasoning that lay behind the text in the Standard, but the reader could be forgiven for thinking that there is over-much concern with assembler-level efficiency for present-day tastes. REAL was not present in X.409, being added in about 1986.
There are few difficulties in the definition of the set of abstract values the type contains. Formally, it is the set of real numbers that can be expressed as M times B to the power E where M and E are finite positive or negative integers and B is 2 or 10, plus other specified values (see below). These sets do, of course overlap, but do not include values such as one-third or PI, although they contain value arbitrarily close to these real numbers. There was some discussion at the time about making provision for the precise identification of "special" values like PI, e, etc, and the encoding of REAL has hooks for extensions to support this, but such extensions have never been progressed. The only "other specified values" referred to above that are included in the encoding (and hence in the abstract value set) of REAL are PLUS-INFINITY and MINUS-INFINITY.
The encoding for the B=10 set of values was determined by reference to an existing ISO standard, and is essentially a binary-coded-decimal encoding common to COBOL systems. The B=2 case corresponds to normal floating point hardware units, and is rather more interesting. The requirements of such an encoding differ significantly from standardization of floating-point formats for almost any other purpose. In particular, efficiency or numerical accuracy in the performance of arithmetic operations is not an issue. The dominating factor has to be the question "How efficient can the code be that has to transform from existing actual floating point hardware formats to and from the transfer representation?". Thus the existence of an IEEE standard for floating point arithmetic units has little relevance. Whilst this may well be a highly appropriate standard for new hardware systems or software emulation to adopt, it is a long way from being easy to transform into and out of unless your existing system is already an IEEE floating point unit. In 1986, and still today, there was/is no sign that floating point units that conform to the IEEE Standard will be the only ones in existence in the foreseeable future. Thus the IEEE Standard does not satisfy the requirements.
Let us take an example of what has to be considered. A format using a one's complement mantissa or a two's complement mantissa or a sign and magnitude mantissa could be adopted. It is clear that if sign and magnitude is adopted for transfer, real systems with any of these approaches could very simply use the floating point unit to determine the sign and negate negative values to provide data for a sign and magnitude representation. On the other hand, producing a one's complement or two's complement representation from a floating point unit that uses sign and magnitude is a much more lengthy and difficult job. Thus the answer is clear: sign and magnitude is right for transfer.
A similar consideration led to the introduction into the transfer format of an extra field not found in any real floating point architecture. The transfer consists of five fields packed into octets:
S The sign of the number (+1 or -1)
M The mantissa, a positive integer of
unlimited length
B The exponent base (2, 8, 16, reserved)
E The exponent, a two's complement integer
of size one octet or two octets or three
octets, or with a length field of one
octet encoding the length of the exponent
F A scaling field of two bits.
The value represented is S multiplied by M times B to the power E, multiplied by two to the power F. Why this last provision? If a floating point unit is asked to dump its accumulator into a set of main memory octets for transfer, the exponent will appear somewhere in the set (sometimes at the start, sometimes at the end), but is always short enough to be easily manipulated by register arithmetic and so is no problem. On the other hand, the mantissa will also appear somewhere in the set of octets, usually at either the beginning or the end, and there will be an implied decimal point somewhere within the mantissa encoding. The mantissa will often be too big to manipulate easily with register arithmetic, so shifting it should be avoided. It is a simple (fixed) subtraction to the exponent to move the implied decimal point to the end of the mantissa, and hence to transmit the mantissa as an integer. The problem is, however, that we would like to use the octets containing the mantissa as the octets to be used to transfer M, zeroing any bits in those octets that are before the start of the mantissa, or between the end of the mantissa and the end of these octets. The decimal point needs positioning (by subtraction of a fixed value from the exponent) at the end of these octets. The problem is that for a single unit subtraction from the exponent, the implied decimal point moves one bit position if B=2, two bit positions if B=4, three bit positions if B=8, and a full four bit positions if B=16. Thus the nearest we may be able to get to positioning it where we want it is to a position which is zero to three bits away. Zero to three can be encoded as two bits, and the provision of F is precisely to allow this value to be represented in transfer. Reconstituting the floating point number (in a different hardware representation) on receipt by multiplying by 2 to the power F is a simple table-look-up and floating point multiply, and poses no efficiency problems.
The text in an informative annex in the Standard encourages the transmission of the mantissa without shifting, even if this implies the transmission of additional zero bits at the end of it, giving the implication of a higher precision in the original format than was actually present. This has been (and continues to be) criticised by one National Body of ISO, with repeated inputs requesting that the annex be changed and text added to make it clear that low order zero bits should not be transmitted, even if this would mean shifting the mantissa. The text, however, remains (in early 1992) as described above.
An interesting (?) feature of ASN.1 is its macro notation. In 1982, when an early draft of X.409 was presented to ISO Experts, it looked very similar to what it is now: a notation for defining abstract syntaxes, that is, sets of abstract values, that is a notation for defining data types (plus the encoding rules). In the next version, however, its nature suddenly dramatically changed with the introduction of a major new piece of syntax (with no associated encoding rules) into the language, purporting to allow the definition of "operations". The reason was simple. X.409 was never seen by CCITT workers as simply a language for defining data structures. It was seen as a language providing notational support for the whole of the X.400 work, whatever that might imply. Data structure definition for protocol messages was an important part of that, but was not the whole requirement.
The additional requirement came from a piece of work which later become known as ROSE (Remote Operations Service Element), and which was originally published in CCITT Recommendation X.410. (Like ASN.1, it was later moved to the X.200 series as part of the main-stream OSI infrastructure.) The new syntax, hard-wired into the X.409 text, introduced notation that allowed an ASN.1 user to write things such as that shown in figure 8.7: Addition of OPERATION notation.
The ROSE specification provided a general carrier mechanism to invoke an operation on a remote system, and to return a normal result or an error code from that system. Each operation required to have associated with it an integer value identifying the operation (in later years this was changed to an object identifier value), an ASN.1 data type to carry the arguments of the operation, another ASN.1 data type to carry back the (normal) results of the operation, and a series of possible error codes, each of which again had associated with it an ASN.1 datatype to carry parameters associated with the error code.
The ROSE group did not define any actual operations. That was for the users of ROSE (the main-stream X.400 workers) to do, but they did want a simple and defined notation specifying that would let such other workers define operations to be invoked using ROSE. The syntax of figure 8.7 was designed to provide precisely that.
When ISO Experts saw the new text, there was immediate and fairly wide-spread opposition. Part of it stemmed from a lack of understanding. What had defining operations to do with a notation for abstract syntax definition? (Fairly) clearly, given that there were no associated encoding rules, nothing! (Except that the extended notation had old ASN.1 data structure definitions for arguments, results, and error parameters of operations as the major part of any use of the extended notation.) Part of the problem was the differing perception of the scope of X.409, but part of the problem was a very real concern that if the notation was extended to allow the definition of "operations", simply because they needed data types to be defined as part of their definition, then what else might there be a need to extend the notation for? What was its real scope and bounds? This proved a perceptive objection with hindsight.
At one point, it looked as if there would be separate ISO and CCITT standards, one without the "operations" syntax, and one with, but then CCITT withdrew the proposal to add this new syntax, and instead proposed a general-purpose macro notation such as most self-respecting programming languages possess. This was hard to resist; the macro notation text was hard to understand, but it appeared to introduce no new concepts; and it was late in the day with the 1984 Recommendations nearing finalization. The macro notation proposal was accepted. In fact, it is wrong to equate the ASN.1 macro notation with any conventional macro notation in programming languages, which is usually largely an intelligent textual substitution tool. The ASN.1 macro notation purported to allow a user to define a new syntax for the definition of ASN.1 types and values. The new syntax could be anything the user wished. The full power of BNF (Backus-Naur Form), the notation often used to define programming languages, was made available to the ASN.1 macro definer. Thus it was (and is) possible to define an ASN.1 "macro" which would allow a piece of syntax identical to Fortran, Cobol, Pascal, or C to be legally inserted in the middle of an ASN.1 module as the purported new notation for an ASN.1 type or value. It was a very powerful (and dangerous - syntax that is arbitrarily hard to parse, or even down-right ambiguous, could easily be defined) tool whose capabilities have never been even nearly fully exploited in any actual use.
When defining a macro, the definer gave it a name (OPERATION for example!) and specified the new syntax for type definition and the new syntax for value definition. Thereafter, the keyword OPERATION, followed by the new type syntax, could be used anywhere a normal ASN.1 type definition could be written, and the corresponding new value syntax could be written anywhere a value of that type could appear (for example after DEFAULT). Unfortunately, the nature of the macro definition mechanism made the actual type being defined by the new type notation dependent on the parsing of a value using the new value notation. As type notation can and does frequently appear in ASN.1 with no corresponding value notation, this was clearly something of a flaw!
The important point, however, from the point of view of ROSE, was that the general form of value assignment in (old) ASN.1 looked like figure 8.8: General form of value assignment. By introducing the macro notation concept and defining an OPERATION macro and an ERROR macro, this immediately allows the syntax:
look-up-operation OPERATION new type syntax
::= new value syntax
which, surprise, surprise, (with an appropriate definition of the new type syntax and the new value syntax in the OPERATION macro) is just the syntax proposed for addition to ASN.1 in order to support the ROSE requirement for a notation to define operations!
For a couple of years, the macro notation was thought by many to be a curiosity which happened to satisfy the needs of ROSE, but which was best swept under the carpet and forgotten about. But then, round about 1986, there was suddenly an explosion of macro definitions. Just about every group of CCITT Experts defining OSI protocols realised that they had a need for a notation (which would usually, but not always, include some real ASN.1 type or value definitions) to define something, and that the ASN.1 macro notation provided them with a fairly formal way of specifying that notation. But there was little or no semantic underpinning in the ASN.1 text. The macro notation began to be called a chimera - an apparently formal way of saying something, but with any semantic underpinning resting on English language text provided by the users (often absent), and with serious flaws in terms of possible ambiguity. About this time tools began to appear giving good support for the implementation of protocols specified using ASN.1, but because of the lack of any real semantics beneath use of the macro notation, these tools found it hard to support macros other than by treating the syntax defined by macros such as the ROSE OPERATIONS macro as a wired-in part of ASN.1 - precisely what had been proposed in 1983!
The upshot in the late 1980s was considerable opposition in some quarters to the definition of new macros, and to a desire to replace all current macro uses. This had the unfortunate result that a number of new pieces of notation involving ASN.1 types and values (such as the GDMO - Generic Definition of Managed Objects notation) were defined using ordinary English, rather than by the more formal (at least in terms of syntax) definition of an ASN.1 macro notation. It did, however, result in a long close look at just what the real user requirement was: what macros were actually being used for. The result was the introduction of a simple parameterisation into the ASN.1 notation, together with the introduction of the information object class concept and associated syntax. These are described under the "new work" section below.
It would require a full book on ASN.1 (and such texts do exist) to completely cover the Basic Encoding Rules. Nonetheless, the new work can only be properly understood if some of its more interesting features are presented.
The first point relates to extensibility of protocols. From the very beginnings of the ASN.1 work there was recognition that the separation of encoding rules from abstract syntax definition presented pitfalls for the unwary in moving from version one of a protocol to version two of that same protocol, and that such movements would be common, particularly in the early days of OSI standards development.
Suppose the abstract syntax for version one is defined as the values of some type, and the abstract syntax for version two as the values of a type containing precisely the same set of values (with the same semantics), but with some additional values. This can be happen, for example, if some element in a SEQUENCE (or even an outer level type) is changed into a CHOICE of that element or type and some other type, or if new OPTIONAL elements are added to a SET or SEQUENCE. In this case, a user new to the work might expect that the encoding for those values that were common to version one and version two (values where the version one CHOICE is taken, or the additional OPTIONAL elements are omitted) would be the same. Moreover, there can be clear implementation advantages if a version two system can interwork with a version one system merely by avoiding sending values that are in version two only, without having to have two different encodings for version one values - one for use when talking to version one systems, and one for use when talking to version two systems.
Some serious thought about the possible design of encodings will soon enable the reader to understand that the above properties are in no way either automatic or even natural in the design of encoding rules. They require to be carefully designed in, and generally carry a quite high cost in the transmission of redundant information. The design principles of PER (Packed Encoding Rules) - developed in the early 1990s and discussed below - by contrast provide for much less verbose encodings, but lose most of these extensibility provisions.
In order to provide support for such extensibility provisions, BER is a somewhat verbose protocol. It adopts a so-called TLV (Type, Length, Value) approach to encoding in which every element (field) of the encoding carries some type information, some length information, then the value of that element. Where the element is itself structured, then the Value part of the element is itself a series of embedded TLV components, to whatever depth is necessary. This has some important consequences. First, it means that if some element in version one of a protocol is replaced in version two by a CHOICE of that element and some other element of a different type, the encoding for values in version two that were present in version one can be unchanged: no specific bits are needed to say which CHOICE has been taken, as all elements are self-identifying whether in a CHOICE or not. Secondly, the existence of lengths at all levels of nesting means that if, in version two, additional optional elements are added at the end of a sequence it again retains the level one encoding. Even if the elements are not optional, a level one system can still detect the presence of added but unknown elements and ignore them. The addition of new types anywhere in a SET construct has similar properties. Another property that this approach provides for BER is that an incoming bit-stream can be parsed into a tree structure of elements and embedded elements without any knowledge of the actual ASN.1 type to which it relates. As a special case of this, the end of the encoding can be determined without any knowledge of the type. The widespread assumption that BER was the encoding for ASN.1, and the strong properties of BER with regard to extensibility led to (often hidden) assumptions about extensibility properties that were only made explicit by the new work in the early 1990s.
The second main point relates to the general structure of the encoding. The encoding for a type that is a SEQUENCE of a number of other types is constructed by concatenating the complete encodings of the component types and putting a T and an L at the head. This is not a representation of data structures which one will commonly find used for high-level language data structures (particularly if the size of the inner elements depends on the actual value represented). In such cases it would be more common for the outer level structure to be an array of pointers, each pointing to the structure representing one of the elements, and probably using dynamic memory management to permit changes to variable length components. Thus the task of transforming a common internal representation to a BER representation can be a CPU consuming task.
One of the (unfortunate?) consequences of trying to ensure that level two encodings were the same as level one encodings when new values were added to the abstract syntax was the presence in the ASN.1 notation of tags. If the encoding is to be a TLV style, the T has to be determined. Moreover, if the T is to be used to distinguish the elements in a SET (transmitted in a random order), or the chosen alternative in a CHOICE, then it has to be different for all such elements and all such alternatives. But suppose the user wants a CHOICE to be a choice of two INTEGER values (with different semantics). If the encoding of a CHOICE is to be nothing more than the encoding of the chosen alternative (in order to allow elements in version one to be turned into CHOICEs in version two), then there will be nothing to distinguish the two INTEGER encodings, and we have to forbid CHOICEs where the alternatives are the same type. Similarly we have to forbid SET elements in which the elements are the same type. (Note that these restrictions do not arise if we allow the encoding algorithm to assign the T, or treat SET like SEQUENCE and identify chosen items in some other way). The restrictions are, of course, unacceptable, so we need to refine the concept of a type, allowing the user to specify the T part of an element independently of the actual type of that element. This produced the tag concept, which has no counterpart in high level language data structure definition, and is the hardest part of the ASN.1 notation for a beginner to understand. Using this concept, the T part of the encoding is constructed from a tag that is formally part of the type being defined. Tags consist of a class (universal, application-specific, context-specific, and private) and a number (an integer), providing a simple structure to the tag name-space. For primitive types the tag is assigned in the ASN.1 standard from the universal class. In fact, just two classes, universal and one other would have sufficed, but at the time this work was done the concept of presentation contexts was not well-developed, and it looked as if ASN.1 tags might have to be used to separate messages with the same encoding produced by different application designers. A user of the notation can over-ride the tag on any type which is defined by specifying a new tag, in square brackets, as a class name (context-specific has a null name) and a number. Thus:
[UNIVERSAL 29] (only allowed in the ASN.1 Standard)
[APPLICATION 32]
[PRIVATE 45]
[6]
are all tag values that can be put in front of a type reference to change its tag, and hence the T value used when it is encoded. The rules are then (fairly) simple. All alternatives of a CHOICE and all elements of a SET are required to have distinct tags. In practice (as a matter of common style) the user normally (in version one) simply adds tags [0], [1], [2], in turn to every alternative of a CHOICE and to every element of a SET. In version two, however, he/she is careful to retain these tags, and to add new elements with different tags, even if it breaks that pretty sequence, because he/she knows that changing the tag will change the encoding. If tags were hidden and automatically assigned, they would be different in version two from version one.
In fact the Basic Encoding Rules provided two options when a tag was added to some type. In the first option, both tags were included in the encoding, making it possible, from the tags present (the innermost being a universal class tag), to identify the type of a primitive element (integer, boolean, or real) without any knowledge of the type definition. Thus a line monitor, with no knowledge of the protocol involved, could in principle produce a pretty display with integer value as integer values and boolean values saying TRUE or FALSE (for example). However, there would be more octets on the line than are really needed. All that really need be encoded is the outermost type (the one most recently added by the user to prevent ambiguity). Both options were available in 1984, but the default was got wrong.
If all tags were to be encoded, making the type of the element explicitly identified by a universal tag in the encoding, then the square bracket notation was used as shown above. If, however, the application designer wanted only one tag to be transmitted, then it was necessary to write (for example):
[6] IMPLICIT INTEGER
Of course, that is what everybody did want, and specifications produced in 1984 were littered with the work IMPLICIT, much reducing readability of ASN.1 by a beginning user.
In 1988, it became possible to change the default by saying in the module heading "IMPLICIT TAGS" so that simple use of a tag produces that one tag only and the word EXPLICIT has to be included if implicit tagging is not wanted. This has been widely taken up, and the word IMPLICIT is now hardly ever seen with tags on current specifications.
In the work of the early 1990s, a further step has been taken, partly as the result of developing encoding rules where extensibility is not a concern and user assigned tags are completely ignored in the encoding. The words AUTOMATIC TAGS can be included in the module heading, and in this case (if BER is in use), the tags are automatically generated and the user need not include them. Of course the extensibility properties are now lost, but as stated above, this is less of a concern now than in previous years, and the gain is a data structure definition that looks much more like what one is used to in high-level language definition, and that is much more readily understandable by someone new to the work.
The text in this section is based on the Draft International Standards produced in 1992 for the major extensions to ASN.1 that were developed in the early 1990s. There are four main parts:
Whilst this text does not provide a complete treatment of all the new work in the early 1990s, it covers all the major items that an application designer might wish to use, and all the conceptually difficult areas.
The whole concept of layering in the bottom six layers is based on doing part of the total job by defining exchange of information in messages, leaving a "hole" (typically called a user data parameter) to be filled in by the next layer. That next layer defined the message to go in the hole, but again left a hole in its own material, and so on. The architecture of the application layer (discussed in more detail in the next chapter) continues this approach. We do not talk about any further layers, but we do have many protocols which define messages with "holes" in them for other protocol designers to fill in. The difference, however, is in the nature of the holes. In the lower layers (up to and including the Session Layer), most messages were defined with a single hole that would carry a transparent octet string (user data). In the Presentation Layer, there are arbitrarily many independent holes in each message, each hole being capable of holding a presentation data value. We have already briefly mentioned that the Presentation Layer model recognises that some of those presentation data values may contain other presentation data values embedded within them, thus recognising the concept of a hole in a presentation data value to be filled by values from some other (perhaps arbitrary) abstract syntax.
When we come to real application standards, the ability to define data structures with "holes" in them is critically dependent on the abstract syntax notation in use and the support for "holes" in any associated encoding rules. If the "hole" is to carry values from any abstract syntax, then attention must be paid (in the encoding rules supporting the "hole") to the same sort of questions that the presentation protocol had to address: how to carry a collection of arbitrary bitstrings, each of which may not be self-delimiting and may not be octet-aligned, and how to identify the abstract and transfer syntaxes to be used to interpret those bitstrings? And what optimisations are sensible for special cases of octet-alignment, use of the same abstract and transfer syntaxes, or whatever? The discussion of the presentation protocol should have convinced the reader that such issues are non-trivial, and require careful design. In this section we are concentrating on the support for "holes" provided by ASN.1 and its encoding rules.
It is important here to clearly distinguish between the embedding of material at the abstract level, where "hole" is a good term, from the way encodings might operate. A hole at the abstract level could be supported by a "hole" in the bit-pattern of the encoding, embedding the encoding of the inner material in the encoding of the outer. For some approaches to encoding, this would be a very natural approach. Alternatively, the hole at the abstract level could equally well be supported by encodings that carry the encoding of the contents of a hole after the bit-pattern representing the container value. The way encodings operate is not constrained.
It is also important at this stage to point out that a piece of communication is not fully defined until all holes have been filled in. Moreover, where a protocol leaves a hole, it is essential to have some way of identifying what is in that hole in an instance of communication. In the case of the lower layers, the contents of the hole in a pure OSI stack will be the next layer of OSI protocol (with its user data). If other protocols (such as TCP/IP protocols) were to be carried above a partial OSI stack, then some means is needed to identify to a receiving implementation the actual protocol being carried.
There are in general three mechanisms used to do this in the lower layers:
The last case is the ultimate fall-back, but suffers from the fact that the values used to identify protocols A and B (say) are not universally defined, but will vary from receiver (typically) to receiver. The TCP/IP concept of "a well-known port", is a variant on this theme that attempts to make the addressing information used for particular protocols consistent across all systems.
In the application layer, there are the holes in the presentation layer to worry about, but also the possible holes in presentation data values to be filled by further presentation data values that may themselves have further holes. In this case, the contents of individual holes in presentation data values may be identified by the containing material, but the fall-back provision (which also determines the contents of the holes in the Presentation Layer) is the carriage within the Association Control Service Element (ACSE) (discussed later) of an application-context value: an ASN.1 object identifier. This object identifier references a specification that provides any additional information needed to define completely the contents of any undefined holes and the total behaviour of the application over the presentation connection.
The ASN.1 Standards have changed considerably from 1982 to 1992 in the provision of mechanisms to support "holes". In order to understand these developments we will define (for the purposes of this text - the terms are not used in the ISO standards) two types of hole, and then go on in the next section to look at the mechanisms ASN.1 provides for their support. The first type of hole we will call the ASN.1 datatype hole, and the second the presentation data value hole.
An ASN.1 datatype hole is characterised by the provision of a hole which can only be filled by a datatype defined using ASN.1. The group defining the container does not define an abstract syntax (the ASN.1 type is incomplete). Rather, when a user group defines the container contents, it is the (now complete) ASN.1 datatype (container plus contents) that is used to define an abstract syntax. Thus there may be many different abstract syntaxes defined with the same outer container (one for each contents), but the fact that they have the same container is not visible beyond the pure ASN.1 notation level. The encoding rules applied to the contents are of necessity the same as those applied to the contents. A typical example of this type of hole is the ROSE Standard, discussed briefly earlier and in more detail below. ROSE defines ASN.1 datatypes to be used to invoke remote operations, but they have holes in them to carry information related to the actual operations needed for some application. ROSE does not define any abstract syntax, rather the users of ROSE define their operations (and hence the ASN.1 datatypes to fill the holes), and define and name an abstract syntax which consists of the values of the ROSE PDUs carrying their operations. Clearly some notational support is needed to link together the provision of a hole and the definition of material to fill it. As mentioned earlier, the macro notation has in the past been used to partially support this requirement, in the absence of anything designed for the task.
By contrast, a presentation data value hole represents the situation where the carrier is regarded as complete, even with the hole present, and an abstract syntax is defined for its messages. The ultimate contents of the hole can be from any other abstract syntax (perhaps not even defined using ASN.1), and can certainly have a different transfer syntax from that of the carrier. It now becomes necessary to have some way of identifying the abstract syntax used to fill these holes, and the transfer syntax that has been applied to the material. A typical example of this type of hole is the X.400 electronic mail standard, which provides for the carriage of what is called an extended body part with the mail message. An extended body part might be something like a spread-sheet, a word processor file, an image file, a piece of animation, a piece of video, or a database file. Abstract and transfer syntax definitions (perhaps implicit by reference to some vendor's implementation) are needed if such material is to be carried. Again, some notational support is needed to identify such holes, but there is less need for linkage between the definer of the hole and the group filling it: anything for which an abstract and transfer syntax has been defined can fill it. (The perceptive reader will recognise the implementation and conformance problems this can raise). It is easily said that "anything can fill it", but what is an implementation actually expected to handle? For these sorts of hole, one expects to see a Protocol Conformance Implementation Statement (PICS) provided by an implementor using a standardised proforma provided by the carrier group, with space on the proforma to say (in the case of X.400) precisely what extended body parts are supported by the implementation).
The history of ASN.1 hole handling, by both the ASN.1 group and by the users of ASN.1 (application designers) has unfortunately been an unhappy confusion of these two types of hole, and an only partial solution of the problems raised by holes. The distinction between the two types only began to be clearly recognised in the work of the early 1990s.
There is also another type of (less respectable) hole, introduced in a number of application standards, which we will call the OCTETSTRING hole. In this case, the application designer specifies a field as an ASN.1 octet string for the purposes of defining his/her own abstract syntax, then proceeds to populate the field with the encoding of an ASN.1 type (perhaps defined by some other group) using some fixed encoding rule (usually BER, but sometimes BER followed by the application of some cryptographic algorithm). Use of this mechanism cannot be prevented by the Presentation Layer or by ASN.1 (although text in the 1992 DIS deprecates this use of OCTETSTRING), but clearly does not fit in any way with the spirit of the presentation layer. It prevents any form of transfer syntax negotiation, and fails to carry with the OCTETSTRING either an abstract syntax or a transfer syntax identification. Equally, because a normal type is used to define the hole, there has never been (and probably never will be) any notational support in ASN.1 to link the container and the contents. Its use is to some extent a historical relic (Reliable Transfer Service Element and X.400 - discussed later) from the days of protocols sitting directly on top of the presentation layer, and from the days before the concept of RELAY-SAFE encodings was properly understood, and it will not be discussed further in this book. The reader is, however, asked to avoid introducing such holes in any designs he/she becomes responsible for!
The earliest treatment of holes in ASN.1 (circa 1982) supported only the ASN.1 datatype hole (and that in a very weak way), and preceded the entire concept of presentation data values that emerged circa 1985. The support took the form of an ASN.1 type called ANY . Describing an element of a SEQUENCE as "ANY" meant that someone, somewhere, would eventually say what went in the field. There was no means of identifying the actual content of the field, nor of cross-linking the field and a definition of possible contents. A typical use today (taken from X.500) would be an element of a SEQUENCE construct defined as:
bilateral-information ANY
In this case, it is assumed that two parties to a communication will mutually agree the specification of what goes in this ASN.1 datatype hole when they are communicating using this protocol, and will use knowledge of the address of the corresponding party to determine what the contents are in an instance of communication. The use of address information as a protocol id has been discussed in principle earlier, and is not ideal, particularly if the same agreements are in place with a number of correspondents, or when one correspondent wishes on different occasions to use different material in the hole, but it is the ultimate fall-back when no other provision has been made for identifying material in a hole.
In the case of ANY, the "hole" had to be filled with a type defined using ASN.1, and the Basic Encoding Rules specified quite simply that the encoding of an ANY (for embedding as a TLV component in the encoding of the enclosing type) was the encoding of the type that was chosen to fill it. It was really the robustness of the ASN.1 Basic Encoding Rules (the uniformly applied TLV concept) that made this simple approach work. Because the end of a BER encoding could (and can) be determined without knowledge of the type being encoded, ASN.1 datatype holes could be skipped if necessary without affecting the ability to interpret the rest of the message. In particular, if identification of what was in the hole appeared in some later field of the message, there was still no problem in continuing the parse and locating that information.
Another problem with ANY was that, in the early days, it was often abused by being used to stand for "for further study", or to identify that there would in due course be a further element of a sequence, but the application designers didn't yet know what it should be. If the ANY was marked OPTIONAL, then it could be argued that the protocol was actually implementable, because values where the ANY was omitted were well-defined. But such uses frequently left the reader in doubt about whether there was, somewhere, some other standard that specified the ANY contents, or whether there would be a later specification that would remove the ANY. Such uses are less common today, as protocols have matured.
In about 1984, the problems with ANY were becoming recognised, and use of the raw ANY, or a black hole as it then became colloquially called was deprecated in the ASN.1 Standard, and the construct "ANY DEFINED BY field-name" was introduced. This was an attempt to try to ensure that, whenever an ANY was introduced, some other field "near" to it (at any rate, in the same message) would contain some value (an integer or an object identifier) that would, by reference to some specification, determine the contents of the ANY field. This construct replaced ANY in a number of specifications, but the rather rigid definition of "a field near to the ANY" restricted the take-up of this construct, and many protocols still contained a "raw ANY" at the end of the 1980s. Moreover, whilst this notation did help to ensure that the ASN.1 datatype filling the ANY field (and any associated semantics) was identified somewhere in the protocol, it did nothing to identify where the mapping of the integer or object identifier to the ASN.1 datatype and its semantics could be found. Thus it was really only a partial solution.
At about the same time as the ANY DEFINED BY construct was introduced and the raw ANY was deprecated, another mechanism was introduced called the EXTERNAL type. This was the first attempt to provide notational support for a presentation data value (pdv) hole, although at this time the term pdv was not as current as it is now. The word "EXTERNAL" was used because the idea was that what went into the hole was external to the current specification, that is, external to the current abstract syntax. It could be a value from an abstract syntax defined using some notation other than ASN.1, and even if defined using ASN.1, it might be encoded with different encoding rules from the carrier.
The intent was very clear that this type should carry an embedded pdv, forming a presentation data value hole, but the technical terms which were emerging at about the same time to describe presentation layer concepts were generally not used in the definition of EXTERNAL. Indeed there was, and remains, a body of opinion that wishes to see minimal use within the ASN.1 Standard of OSI Presentation Layer concepts. It can be used as a means of defining data structures in the lower layers of OSI, or completely outside OSI, as well as by OSI application designers. This attitude can sometimes make a clear specification of its use in support of the Application Layer of OSI more difficult.
The early design of EXTERNAL envisaged that the Presentation Layer protocol would specify the message going into Session Service user data parameters as simply the BER encoding of
SEQUENCE OF EXTERNAL
and some tutorial texts still say that this is indeed the presentation protocol. In fact this definition never appeared as an actual standard, because if the presentation data values in the user data parameter of a P-service primitive were all BER encodings, and were all from the same presentation context (a common case), this data structure contains a lot of redundant information, in particular, the presentation context and the T and L of the EXTERNAL are repeated for every presentation data value in the list. So the presentation protocol actually abandoned ASN.1 for encoding the user data parameter and defined that part of its protocol in ordinary English, copying much of the text (with changes) from the ASN.1 definition of EXTERNAL.
There were mistakes made in the design of EXTERNAL. The presentation concepts and terms were still maturing, and it was not made clear that it carried an embedded pdv. Moreover, there were only three options provided for identifying what filled the hole, neither of which was wholly satisfactory.
One option was to carry an integer which (in rather obscure text) was intended to be a presentation context identifier for a context in the defined context set on this connection at the time the message containing the EXTERNAL was transmitted/received. This was clearly not RELAY-SAFE, to use modern terminology (this issue is discussed further below), and the X.400 Standards (in some cases by folk-lore and rumour, rather than explicit text), avoided this option, as relaying of material was fundamental to their operation.
The second option provided for EXTERNAL allowed the presentation context identifier to have with it a transfer syntax object identifier. This was to cover the case (on P-CONNECT or P-ALTER-CONTEXT) where a presentation context had been proposed, but the transfer syntax had not yet been agreed.
The third option provided for EXTERNAL was to carry a single ASN.1 object identifier that was intended to identify both the abstract and transfer syntax of the embedded value. This was, in retrospect, undoubtedly an error, and the EMBEDDED PDV construct in the 1992 DIS contains two object identifiers, quite straight-forwardly specifying the abstract and transfer syntax of the encoding. (In order to provide backwards compatibility with EXTERNAL, however, the transfer syntax object identifier is optional.) Because the X.400 (electronic mail) use of EXTERNAL had to assume a fixed encoding of the contents of the EXTERNAL (no transfer syntax object identifier), static text was needed to determine the transfer syntax. Typically, if the contents of the EXTERNAL was ASN.1-defined at the abstract level, then one could either define use of BER, or one could define use of the encoding rule negotiated for the outer level encoding. Of course, in 1992, the two definitions would in practice give the same result, and text saying which was intended was often missing in uses of EXTERNAL. If, however, the contents of the EXTERNAL was not ASN.1-defined (an extended body part in X.400, for example) then a specific definition of transfer syntax has to be associated with the object identifier when one is assigned to identify a body part. If, for example, the body part was a LOTUS-123 spreadsheet, or a dBase IV file, or a WordPerfect 5.1 file, then the object identifier assigned to the body part has to identify not just the abstract object, but some specific encoding (for example, that of MS DOS) of the abstract object that was being carried. If a Mac encoding was wanted, then a further object identifier would have to be defined, and there would be no obvious link between the two. Thus the original EXTERNAL encouraged the use of a single identifier for the combination of abstract and transfer syntaxes, ignoring the concepts of the Presentation Layer. The 1992 DIS attempted to correct this situation before it was too late by including a pair of object identifiers in the EXTERNAL replacement (the EMBEDDED PDV construct), whilst allowing the transfer syntax object identifier to be omitted for backwards compatibility with the old EXTERNAL.
The main message of the Association Control Service Element (ACSE) is carried in the first presentation data value of the P-CONNECT request. Other application specifications contributing to the connection could have carried their messages on subsequent presentation data values of the P-CONNECT request, but in the early days of ACSE use, it was often regarded as almost another layer. In particular, it provided for embedded pdvs by having a user data parameter defined as:
SEQUENCE OF EXTERNAL
and other application designers chose not to place their initialisation exchange directly in the P-CONNECT presentation data values, but rather in one of the ACSE EXTERNAL fields, regarding themselves as the sole users of A-ASSOCIATE, and ACSE as the sole user of P-CONNECT.
We see then that the usage of EXTERNAL was (in the late 1980s) a bit of a mixture of simply filling in an ASN.1 datatype hole with the filling in of a presentation data value hole.
In the 1992 specification, both ANY and EXTERNAL were deprecated. An EMBEDDED PDV type was provided to clearly and directly support the inclusion of presentation data values from arbitrary other abstract syntaxes, with identification of their transfer syntaxes, and a separate mechanism (information object classes) was introduced for handling ASN.1 datatype holes, linking the container to the contents, and identifying the contents.
One of the problems with the handling of embedded pdvs relates to material that is being stored/relayed from one connection on to another, either in support of some relaying protocol like X.400 (electronic mail), or where material is deposited on a file server and later collected. If the relaying/storing system knows enough about the material to convert it to "pure information", and re-encode in a possibly different transfer syntax, then there is no problem. Frequently, however, we require a design which does not require such detailed knowledge on the part of the relay/storage system, which wishes to handle the material transparently with no capability to change the encoding. It is clear that end-to-end negotiation of transfer syntax using the presentation protocol to perform the negotiation of transfer syntax is not possible in relay/storage cases, but mechanisms based on prior knowledge or on use of X.500 can be used to select an appropriate encoding for the material that is being stored/relayed. It remains, therefore, to identify the material and its encoding in a reasonably efficient manner.
For an outer level presentation data value (even if being relayed/stored), identification can be performed by establishing a presentation context to identify the abstract and transfer syntaxes, and transmitting the material in that context. The relaying/storage system merely needs to ensure that an equivalent presentation context (same abstract and transfer syntax) is established for forwarding/retrieval.
More commonly, the material being relayed will be an embedded pdv (A say), and that embedded pdv may contain further embedded pdvs (B say). It is the case of these further pdvs (B) that is particularly hard to handle using the presentation context. Suppose they were carried in an ASN.1 EMBEDDED PDV type, and that a presentation context was established for them, with the presentation context identifier in the encoding of the embedded pdv. What this means is that there are references from inside a pdv (A) (that is being relayed with no decoding and no understanding) to the external environment in which it was received (a presentation context on that connection). Such references are completely invisible to a system transparently relaying pdv A, and the only solution would be to establish an identical entire defined context set for forwarding/retrieval. This is not really feasible, and such an encoding is not relay-safe . We can define, then, a relay-safe encoding of a pdv as one such that any embedded pdvs (or pdvs embedded in them) make no references to presentation contexts established on this connection. In other words, the abstract and transfer syntax object identifiers of any embedded material must be explicitly present in the pdv being relayed (in the relay-safe encoding). Unfortunately, despite the relative compactness of the ASN.1 object identifiers, this can introduce unacceptable overheads if there are a lot of small embedded pdvs with the same abstract and transfer syntax, a situation which will arise quite frequently in handling character strings using the mechanisms provided in the 1992 DIS.
What is needed for efficient encoding is some indirect indexing mechanism, comparable to the establishment of a presentation context and use of the presentation context identifier, but with the table that is being indexed carried within the relay-safe encoding. This was provided in the ASN.1 encoding rule extensions and new encoding rules defined in the early 1990s. Thus for any particular style of encoding rule (see later), there is typically a basic version, a relay-safe version, and a version that is both relay-safe and canonical (no implementation options in the encoding).
If this approach is considered a little more, the reader will recognise that what is effectively happening is that some of the presentation layer functionality (definition of a presentation context) that was previously carried out at the connection level and applied to all pdv's on that connection is now being carried out at the level of a pdv, and applied to all the pdv's carried in that pdv (and so to any depth). For relay-safe encodings, the presentation connection merely sets up the environment for the outermost encodings. For embedded pdvs, the environment for their encoding is carried in the encoding of the immediately enclosing pdv. This can lead the reader to ask "Have we moved to an architecture where the presentation layer is in some sense no longer a single layer, but is rather recursively introduced whenever embedded pdvs occur?" This will be discussed further below when the application layer architecture is treated in detail.
Let us now return to the notational support needed to tie together the introduction of a hole and the definition of material to fill that (and precisely that) hole.
When the then current uses of macros was examined in the early 1990s, it became apparent that in most (not quite all) cases, they related to ASN.1 datatype holes: quite frequently to raw ANYs, possibly to ANY DEFINED BY constructions, and sometimes to EXTERNALs which were being used to provide an ASN.1 datatype hole and not to provide for an embedded pdv.
In many cases, there was a single ASN.1 datatype hole, and an associated object identifier field to identify the type that was put in the hole. (This was the case where EXTERNAL was most often used, and where the 1992 INSTANCE OF .... construction was the appropriate replacement for the EXTERNAL.) The macro introduced a syntax that included the name of the class of objects being carried in the hole, and the specification of the ASN.1 type of the object and an associated ASN.1 object identifer to identify it. An example is given in figure 8.9: Notation defined by a simple macro. Note that whilst the macro enabled a ..... object to be specified and identified, the link to the actual EXTERNAL or ANY carrying that object was distinctly tenuous.
In other cases, there was a more complex situation, with a number of related holes to be filled, and additional information collected by the macro syntax that did not directly relate to the ASN.1 datatypes filling the holes, but rather selected some optional procedures or processes in the carrier protocol concerned with the handling of objects of this class. A good example here is the ROSE use of macros, where there is an ANY DEFINED BY field in the "invoke" message which needs an ASN.1 type defining to carry the arguments of the operation, another in the "return result" message which needs a type defining to carry the result of the operation, and another in the "return error" message which needs ASN.1 types defining for each possible error return to carry parameters associated with a particular error. In addition, there needs to be an identifier assigned for the operation being defined, for each of the possible errors a set of operations might produce. ROSE also used the macro syntax to collect details of linked operations: operations Y1, Y2, ... which (as a result of system A invoking operation X at B) could be invoked by B at A. Operations Y1, Y2, .... are the linked operations for X. The complete definition of all the information which needed to be provided when defining an object from the class of objects called ROSE operation was provided by a single use of the OPERATION macro (which might reference the names of errors), and the complete definition of the information needed to define an object from the class of objects called ROSE error was provided by a single use of the ERROR macro. These macros provided all that was needed to complete a whole set of related holes, and to provide any additional semantics such as specification of the linked operations.
This approach worked quite well, and the ROSE-defined OPERATION and ERROR macros and their associated syntax were known and loved by many application designers, but it suffered from two problems: first, the link between the holes that were filled by the macro and the uses of the macro itself was tenuous, and in particular was informal and could not be supported by the growing body of ASN.1 tools that assisted in OSI application layer implementations; secondly, where a macro was used to identify a complete set of things that filled a hole (or holes), such as a set of ROSE errors and operations, there was nothing in the notation to relate these definitions to the set of values in some particular abstract syntax specification. Words were used like "the abstract syntax is defined as the set of values of the ROSE datatype, with the holes filled by the operations and errors defined in the body of this Standard". Or more commonly, such words were not used, but merely implied. There was the further problem, identified earlier, that the macro approach gave complete freedom to designers to specify their own syntax for collecting the information needed to define an object from some class. This not merely led to dissimilar syntax defined by different groups for doing the same sort of thing (for example, separating lists of values by comma or by vertical bar), but also left the definer free to specify syntax that could be very hard to parse by a machine parser, and made the ASN.1 syntax completely open-ended.
The 1992 DIS removed the macro notation as a normative part of the Standard, leaving its definition as an informative annex to enable readers to cope with historical material that still used macros.
The replacement provision addressed all the above problems, while retaining a syntax for defining objects of some specified class that could be tailored (within reasonable limits) by the group defining the information to be collected for that class of object.
The basic concept is of the Information Object Class, and defining such a class is equivalent to defining a macro. The definer determines the nature of the information that is to be collected, and (within rigidly defined limits) specifies the syntax to be used for collection. A model which proved helpful in the development of this work is of a table, whose form (columns) is determined by the definition of the object class. Thus column 1 might be defined to hold an ASN.1 object identifier value to identify an operation, with column heading "&id"; column 2 might be defined to hold an ASN.1 type with column heading "&Arguments", column 3 likewise might be defined to hold an ASN.1 type with column heading "&Results", and column 4 a set of references to objects in the ERROR class (a separate table), with column heading "&Errors". (The & symbol was introduced as the first symbol of a table heading to enable human users to clearly distinguish such a thing from an ASN.1 type or value reference.) Each row of the table then defines one object of the OPERATIONs class. figure 8.10: Definition of the OPERATION class shows the way this information object class would be specified. Note the "with syntax" clause that is used to define the way the information is to be collected. This allows only a very simple keyword/value approach to defining the collection syntax, with square brackets denoting optional parts of the syntax, but in fact proved sufficient for syntax defined in this way to be almost as user-friendly as that defined by a macro (but much easier to process). The corresponding definition using macros would have been as shown in figure 8.11: The equivalent macro definition. No attempt will be made to talk the reader through that figure, and if it is totally incomprehensible, don't worry!
With that class definition, it is now possible to define objects of that class. figure 8.12: Definition of objects of class OPERATION shows two operations (rows of the table) being defined using the new notation, and figure 8.13: Equivalent notation using macros shows the way they would have been defined using the macro definition. Note in particular in the new work the new syntax is delimited by a pair of round brackets, whereas using the old macro notation, the only way the end of the new syntax could be found was by performing a parse as specified in the macro definition (which might, of course, appear much later in the material being processed, as ASN.1 allows forward references everywhere). figure 8.14: Defining a table of OPERATIONs shows an assignment that gives a collective name to the resulting table (the set of four operations we have here defined). This was not present in the use of macros.
This has addressed the syntax issues, but what about tying the definition of a class to the holes it is associated with? How does one replace the ANY and ANY DEFINED BY constructs? Let us consider a simplification of the ROSE protocol. figure 8.15: Definition of a PDV with a "hole" shows a simplified version of the ROSE invoke message as it appeared in the late 1980s. There was a tacit understanding (partially supported by text concerning macros) that the OPERATION keyword meant the OBJECT IDENTIFIER type, and was the operation identifier, and that the ANY carried the arguments datatype defined for that operation. The first step is to identify these fields as containing values from columns of the OPERATION class table. This is shown in figure 8.16: Tying the hole and id together, where it is now clear that this particular ANY and this particular OBJECT IDENTIFIER are determined by the definition of an OPERATION information object. Moreover, we can add what is called a relational constraint which specifies that the value in the "identifier" field and the value in the "argument" field have to be related by being values from the same row of the table "My-ops" (see figure 8.17: Identifying a table). The reader will appreciate how this has closed the loop, enabling a precise statement of how the hole is to be filled, and hence a precise statement of the abstract syntax.
There is just one problem with what has been presented so far: the definition in figure 8.17 has to appear in the ROSE Standard, but My-ops and its associated definitions has to appear in the Standard produced by some ROSE user. Moreover, there will typically be multiple such definitions by different groups of ROSE user.
This is addressed by the parameterisation of a piece of ASN.1 specification. Parameter substitution is relatively well understood in computer science, and is often what macros for text manipulation are actually all about. Any type, value, or table which might be otherwise explicitly included as part of an ASN.1 specification can instead be represented by a parameter. In the case of ROSE discussed above, we parameterise the ROSE datatype with a parameter that is a table (called Defining-Table) of information object class OPERATION as shown in figure 8.18: Parameterising the definition, and then in the user standards the datatype used to define the abstract syntax for the user's application is defined by applying the actual parameter My-ops to the parameterised ROSE-invoke thus:
ROSE-Invoke { My-ops}
In fact, parameterisation of ASN.1 specifications turned out to have two additional beneficial spin-offs. First, there were one or two uses of the existing macro notation where the macro was in fact being defined precisely for the purpose of parameterisation and parameter substitution, so that such a feature was needed for the basic macro replacement work. Secondly, parameterisation enables bounds (particularly bounds on integers, number of elements in a SEQUENCE OF, and so on) to be left as parameters in a base standard, and to be supplied later, perhaps with several variants for different environments. The actual parameters can be supplied at the time the abstract syntax is defined (in which case the protocol is tightly defined, but possibly with several abstract syntaxes for the different ranges of bounds), or can even be left as parameters of the abstract syntax, their implemented values being specified in the PICS (Protocol Implementation Conformance Statement) produced by an implementor, and/or required values can be referenced in procurement statements. This helps with what has long been a trouble-some area in OSI. Implementations do have limits, but there is a reluctance to put these into the base standard, because that can unnecessarily tie the standard to current technological capability, and also because appropriate bounds and sizes are often heavily dependent on the environment in which a standard is used. On the other hand, clearly identifying where implementation variation might occur is obviously important. Parameterisation serves all these purposes.
Another troublesome area in the OSI work is that of character repertoires. If an international standard is being defined, it is clearly inappropriate to specify text fields as fields of characters from the Latin alphabet. Even within Europe, systems that supported only the ASCII or the EBCDIC character set (very common in the 1970s and 1980s) were incapable of covering any of the major languages apart from English. But implementing support for fields that can contain Japanese and Chinese and Greek and Urdu and Hebrew (to name but a few!) characters can be rather hard, depending on the precise definition of "support".
The problem is not entirely originated by ASN.1, and cannot be completely solved by ASN.1, but notational support in this area is needed. ASN.1 went through three main iterations in attempting to address this problem.
The earliest text (X.409 in 1984), had a limited range of character types defined covering basically a very limited character set, the ASCII character set, and (surprise, surprise - remember the Transport and Session and Presentation discussion?) the Teletex character set defined in CCITT Recommendation T.61 and the Videotext character set defined in T.100 and T.101. T.61 was interpreted in 1984 as allowing ASCII and Japanese, but other character repertoires were explicitly added to it progressively in the late 1980s and the early 1990s, and it now contains quite a broad range of character repertoires.
The first ISO standard for ASN.1 took a somewhat different approach to this area. There was in existence at that time (and still is) something called colloquially "The International Register of Character Sets", or more correctly "The International Register of Coded Character Sets to be used with Escape Sequences". This was a collection of about 110 register entries, each listing the complete set of characters in some character repertoire, together with code to identify each repertoire, and an encoding for each character within it. For most of the entries the encoding structure used a single octet for each character, and the code tables had the same structure as those normally used to define ASCII (128 positions arranged in eight columns of 16 rows, with control characters in the first two columns and the delete character in the bottom right). Most (but not all) languages of the world were registered, so an arbitrary character could be encoded by using the ASCII "ESC" (standing for "escape") - present in that code position in all entries in the Register - followed by the assigned codes to reference a register entry, followed by the encoding of the desired character or characters.
The ASN.1 work in 1985/86 took this register as its base. Existing character types (and in particular TeletexString) were redefined to reference the Register, and new types were added to enable the full generality of the Register encoding to be used in a field.
Problems arose in the late 1980s from two sources. First, the character sets recognised in T.61 were greatly extended, giving pressure for a similar extension to the corresponding ASN.1 type (which was now defined not by reference to T.61 but by reference to the International Register, and hence was not automatically affected). Secondly, there was increasing recognition that, no matter what one meant by "support", a field which was defined to carry any character from the International Register (which was continually being extended) was hard to support in an implementation. Thirdly, and most importantly, SC2 (Sub-Committee 2, the ISO group responsible for character set standards) had embarked on an ambitious programme to define a completely new structure for character set encoding which would accommodate in one structure all the languages of the world, with defined subsets for the most common requirements (such as the set of European languages). This used a coding structure based on two octet or four octet character encoding, and was entitled "Universal Coded Character Set", and was given the number ISO 10646 out of sympathy for ISO 646, the old and well-beloved standard that underlaid ASCII and the International Register. This work (after some quite serious controversy) came to a conclusion in 1992.
ASN.1 introduced a new datatype (called UniversalString), and married together the existing ASN.1 subtyping mechanisms with the defined sub-types of ISO 10646 to give good support for this new standard. It is now possible to specify a field in an ASN.1 type as carrying any specified combination of the defined subsets of ISO 10646, or even to define new subsets. The conformance statement of ISO 10646, reflected in the ASN.1 text, does however forbid use of ISO 10646 unless the implemented subset is specified. In ASN.1 use, this means that UniversalString is required to be subtyped, although the subtype specification could involve a parameter that is only determined by the PICS (the implementor), not by the base standard. This is the recommended way of using UniversalString in an OSI application design, and further reinforces the importance of the parameterisation mechanisms.
However, these discussions led to a much closer look at the whole question of appropriate character set support, with a strong liaison statement from the Remote Database Access (RDA) group that they required to be able to negotiate the character repertoire to be used as part of connection establishment, or even later.
The result of these discussions was the inclusion in the 1992 text of the CHARACTER STRING datatype, supported by the (new) concepts of a character abstract syntax and a character transfer syntax. A character abstract syntax is largely synonymous with character set or character repertoire, and the character transfer syntax with the encoding of that character set. The important difference, however, is that use of these terms implies the allocation of ASN.1 object identifiers to identify the abstract syntax (repertoire) and the transfer syntax (encoding), and the ability either to name repertoires and encodings or to negotiate them by the definition of presentation contexts. This is a very powerful feature. It not only allows base standards to be written and implemented without placing early constraints on the character repertoires to be used, but it also makes ASN.1 (and hence the application designs using it) much less dependent than hitherto on the vagaries of character set standardization. All that is required if another new character set standard is produced is for that standard to allocate ASN.1 object identifiers for character abstract and transfer syntaxes, and it automatically becomes available as far ASN.1 and application designs are concerned (getting implementation support does, of course, remain another matter).
In fact, there are other SC2 character set standards in addition to ISO 646 and ISO 10646, which had previously been ignored by ASN.1. Support for these now merely (!) requires an addendum to them to define the appropriate character abstract and transfer syntaxes. A (normative) annex to ISO 10646 performs this function for all the combinations of all the defined subsets of ISO 10646, and serves as an illustration for other standards. The definition is algorithmic, with a separate object identifier for all possible combinations of the defined subsets. Again, however, it will be the market-place that will decide which combinations people actually demand in procurement, and which implementors choose to support, but ASN.1 (and any application layer base standard using it) is off the hook.
A brief outline of the structure and approach of the Basic Encoding Rules was given earlier in this chapter, but it is appropriate here to give a brief mention of other encoding rules that emerged in the early 1990s.
Almost the whole of the Presentation Layer work is predicated on the idea of negotiating transfer syntaxes, and hence on there being multiple transfer syntaxes defined. During the whole of the 1980s, such negotiation was a nice theory, but never happened in practice. There was one, and one only set of encoding rules for ASN.1 (the Basic Encoding Rules), and implementors were sufficiently busy producing standards that would interwork with other vendors that there was little interest in defining vendor specific encodings which were close to local representations.
In the early 1990s, however, there was a growing interest in the question of the standardization of appropriate transfer syntaxes and the provision of better encoding rules.
There were a number of viewpoints. At the one extreme there were those that were horrified at the apparent verboseness of the TLV encoding of the Basic Encoding Rules where (apart from extensibility issues) the T part is largely overhead and the L part (given the presence of subtyping) is also frequently unnecessary. At the other extreme there are those that argue that the maximum overhead in BER for most uses is probably no more than 100% (twice as many octets as necessary), and probably in practice rarely more than 50%. What is a factor of two in octets? Factors of ten or more in line-speed come every few years, so .... Moreover, if there were a proliferation of encoding rules, open interworking could be prejudiced because not everybody would implement the same set. Another attitude recognised the importance of optimised transfer syntaxes, particularly for things like FTAM (File Transfer, Access, and Management) Document Types, or ODA (Office Document Architecture) documents, or perhaps X.400 Body Parts, but questioned the value of better ASN.1 Encoding Rules: greater gains could (in this view) be obtained by hand-crafting some transfer syntaxes to optimise common cases for these sorts of transfer. In the middle were those that saw the importance of having a number of internationally standardised encoding rules for ASN.1, making appropriate trade-offs.
By 1992 there had emerged a recognition that at least one new set of encoding rules for ASN.1 was needed (and perhaps more). There were two dimensions to the problem.
One was the basic structure of an encoding, with three approaches being discussed: Basic Encoding Rules (already in place), Packed Encoding Rules - PER (optimised for bits on the line), and a set of LightWeight Encoding Rules - LWER (optimised for the CPU cycles needed for encoding and decoding). These are important concepts discussed extensively later.
The other dimension related to the need for special features in the encoding. Two of these special features were recognised, and could be considered with any of the three basic approaches to encoding.
The first has already been discussed at some length: making the encoding relay-safe. The only real issue here is whether one needs (apart from BER that has existed in a non-relay-safe fashion for some time) to provide a non-relay-safe version. Perhaps it would be simpler if all encoding rules always produced relay-safe encodings? The counter argument is that if a particular character abstract and transfer syntax is used for embedded CHARACTER STRING datatypes in many small presentation data values in a connection (such as might occur in terminal or windows traffic), it is far more efficient to define an outer level presentation context once and for all and reference it as necessary from the embedded CHARACTER STRING encodings (which is not relay safe) than to identify the character abstract and transfer syntax in every outer-level pdv that is transmitted (which would be relay-safe).
The second special feature is the definition of a canonical encoding, that is, one for which all implementation options have been removed. Why is this needed? The recognition first came in the work on X.500 and X.400. They had a requirement to add an authenticator to an abstract value which would enable a recipient to detect whether that abstract value had been tampered with during transfer. The desire was to accept the presentation layer model that relaying systems might (but need not) change the actual encoding by decoding and re-encoding, but, of course, must faithfully relay the abstract value unchanged. Existing authenticator mechanisms had been developed to authenticate a bitstring, not an abstract value. (Typically such authenticators were produced by using some hashing of the octets in the bitstring into a few octets, and then encrypting these for transfer using a secret encryption key. Without knowing the encryption key, an agency tampering with the bitstring in transfer cannot generate a new correct authenticator for the modified bitstring.) One way to use such a mechanism to authenticate an abstract value is to determine a one-to-one mapping between abstract values and bitstrings, then to authenticate the corresponding bit-string. A one-to-one mapping between a bitstring and an abstract value is in fact nothing more than an encoding/decoding rule with no implementation options in the bit-pattern produced, or a canonical encoding rule. (The Directory work used the term distinguished encoding rule, which meant the same thing.) The way this is in theory used for authentication is first to encode using the canonical encoding rules, then to authenticate the resulting bitstring (which is then discarded) to provide an authenticator for the abstract value, to transmit the abstract value and authenticator (involving encoding it and decoding at the receiving end), then to re-encode the abstract value using the canonical encoding rules to provide a bitstream which can be checked against the authenticator. In principle, this involves double encoding at the sending end (once to get the canonical bitstring and once for transfer), and decoding and reencoding at the receiving end (once to get the abstract value and once to get the canonical bitstring for authentication). Where, however, the canonical encoding is a strict subset of the encoding used for transfer, optimisations are possible in a real implementation which allow the encoding produced for authentication to be used for transmission, and the received bitstring to be used for authentication.
The important thing, therefore, is to ensure that for each of the main encoding approaches (BER, PER, and LWER), there is a normal version, a relay-safe version, and a version that is both relay-safe and canonical.
What then are the main features of BER, PER, and LWER? The following sections discuss each of these in turn.
BER has already been characterised as a TLV encoding. Each primitive type encodes into a TLV. Each constructed type encodes into a TLV with the TLVs of the elements in the V part. All T, L, and V parts are a whole number of octets. The T part unambiguously identifies the element within the context in which it occurs, and is formed from the tags that the user has (if necessary) to assign in order to provide for a T part that is
The T part also contains one bit that identifies whether the V part is primitive or is a series of TLV fragments. The L part is always present, and determines the length of the element, either as an octet count, or by indicating that it is a set of TLV triplets terminated by a zero octet. (The encoding of the T part, and in particular the reservation of the tag [UNIVERSAL 0], ensures that a zero octet can never appear as a valid T.) BER was designed before subtyping was introduced into the notation, and completely ignores any subtype information. Thus if an octet string is specified in the notation as always precisely 8 characters long, this information is ignored, and the length field is still encoded. The encoding of lengths and of integers effectively poses no limit on the size of integers that can be supported (the encoding of the largest representable INTEGER value would take about 100 million years to transmit at 100 terabits per second!). For most T parts, a single octet will be used. For L parts a single octet is used if the length is less than or equal to 127 octets. Thus the T and the L normally put a 2 octet overhead on each element.
PER takes a rather different approach from that taken by BER. The first point is that the T part is omitted from encodings, and any tags in the notation are completely ignored. Potential ambiguities are resolved as follows:
The second point is that PER takes full account of any subtyping information, and will omit length fields whenever possible. Moreover, integers that are subtyped into a range that potentially requires more than one octet, but never more than two (for example, (0..65535)) are always encoded into precisely two octets with no length field. Parts of the encoding (lengths or primitive values) that require more than eight bits encode starting on an octet boundary, but elements that require less than an octet pack together in the minimum number of bits. Thus in BER "SEQUENCE OF BOOLEAN", with 64 boolean values, would encode into an amazing 196 octets, whilst in PER it would encode into 9 octets, whilst "SEQUENCE SIZE(64) OF BOOLEAN" would require only 8 octets. A more realistic example might be "SEQUENCE OF INTEGER (0..65535)", which with 64 two-octet integer values in BER would encode into 259 octets. In PER, it would encode into 130 octets. The sequence
SEQUENCE
{first-field INTEGER (0..7),
second-field BOOLEAN,
third-field INTEGER (0..3)
fourth-field SEQUENCE
{fourA BOOLEAN,
fourB BOOLEAN} }
would encode into precisely one octet (BER would take 19), making it possible in some cases to retrofit a hand-crafted and heavily packed protocol with an ASN.1 definition and a PER encoding, although this was not a major design requirement for PER.
Turning now to LWER, we again find a major change of approach. The LWER work was still immature in 1992, and all that this text can do is to discuss the design approach and some of the problems. The idea of LWER arose from implementors of tools that support the easy implementation of protocol handlers for protocols defined using ASN.1. Such tools read in an ASN.1 type definition and map it into an incore data structure (typically using the C language) which is capable of holding values of that type. The implementor of the protocol then writes a program to write to the incore datastructure to generate (in this local format) the value to be transmitted, then invokes a run-time routine provided by the tool to encode this value into (typically, in the early 1990s) BER, ready for transmission. The process is reversed on reception. The LWER encoding rules are based on the experiences of implementors of such tools to define, as a working design, a mapping of the value of any ASN.1 type into an indefinitely large memory, with dynamic memory allocation, and with a known word-size (16 bits, 32 bits, or 64 bits). To give the flavour, a SEQUENCE of six elements maps into six words in memory. If the element is a boolean or an integer, the word holds the element. If the element is a variable length character string, the word holds a pointer to a block of memory containing the string (with a length count at its head). If the element is a SEQUENCE OF SEQUENCE (the SEQUENCE again being six elements), the word holds a pointer to a block of memory with an iteration count at its head, and holding six words for each iteration, some of which may be integers or booleans, and some of which may be further pointers. The resulting structure is a strict tree. The encoding rules are then obtained by a simple tree-walking algorithm to transmit in a specified order the blocks of memory forming the value tree. In early 1992 there were a number of unresolved issues concerning the LWER encoding, and all that can be done in this text is to mention some of them. The reader who wishes to know more must obtain the latest OSI documents. The first issue relates to the word-size: clearly with the word-orientation of LWER we need at least three LWER encoding rule specifications, one based on a 16-bit word, one based on a 32-bit word, and (perhaps?) one based on a 64-bit word. Then there is the problem that, if one defines the octet order in memory such that a character string goes from low numbered octets to high numbered octets, we find that in some computer systems an integer has its most significant octet first (so-called big-endian), and in some systems it has it last (so-called little-endian). Does this mean we need six LWER encoding rules? And are there not some systems (with word sizes greater than 16) where other permutations of the octets are needed to get the integer value? A more difficult problem arises with integer values that won't fit into the word size. Should the encoding rules (and the model incore representation) be made more complicated to allow pointers to a longer block if the integer value exceeds the word size, or is it acceptable to say that these encoding rules have implicit size restrictions on INTEGER? Or should account be taken of sub-typing? And what about length counts that exceed the word-size? And finally and similarly, how do we model pointers that cannot fit into the word-size, and more importantly how do we flatten the tree structure for transmission? Can we define the tree-walking in such a way that actual pointer values need not be transmitted, merely a flag saying this field is a non-null pointer? It is at this stage impossible to say more about the likely final form of LWER: it is even possible that these problems will cause LWER to be abandoned. Notice finally that LWER will be fast and efficient for encode/decode provided it is used between two similar architectures (two 16 bit machines or two 32 bit machines, both big-endian). Its advantages would be rather less if the communicating machines have dissimilar architectures. The question arises whether there is a sufficiently large class of implementations that would benefit from LWER, or whether it would be better to encourage tool providers to obtain object identifiers and allocate them for their own formats, restricting the use of any particular LWER to interworking between implementations based on the same tool? Notice also that the number of octets on the line will be far higher than PER, and probably higher than BER, particularly for the 32 bit and 64 bit versions. Thus this protocol is only really applicable when bandwidth is not a major concern.
The pressure to develop PER and LWER arose partly from technical considerations, and partly because private organizations were known to be developing encoding rules with similar properties, so that international standardization was appropriate to prevent an explosion in the number of encoding rules in use in the world.
The technical considerations were based on a recognition of the various trade-offs necessary in designing a set of encoding rules. The dimensions listed below were identified as important for evaluating the quality of a set of encoding rules (in no particular order).
Bandwidth: A sensible reduction of bandwidth requirements compared with BER is desirable for heavily structured data (where the ASN.1 overhead can be large compared with the contents of the ASN.1 data types). This is particularly important where operation over low bandwidth channels (for example, radio) is still required. PER scores much better than BER on this dimension, without too many penalties on other dimensions.
CPU cycles: Minimisation of the CPU costs of encoding and decoding is always a useful property. The LWER set of encoding rules score much better than BER on this dimension, admittedly at some cost on the "open" dimension described below, but still with a very useful score overall.
Openness: Encoding rules specific to a single implementation are encouraged for optimising CPU cycles, but clearly score poorly on openness, and are not appropriate for international standardization. Nonetheless, it is possible to identify a number of machine architectures such that vendor-independent standardization of exchanges designed to minimise CPU cycles on such architectures provides very useful standards with an acceptable level of openness, although not as much as BER or PER, but with much less CPU cycle cost. This is the positioning of the LWER set.
Extensibility: Support for extensions to the ASN.1 specification of a protocol without this resulting in changes to the encoding of values that were present in the earlier version of the protocol is sometimes a requirement. BER scores very highly on this dimension, and it is unlikely that any other encoding rule standard will be able to score as well. There are some additional extensibility rules that are informally invoked by some application standards (for example: "If there are elements at the end of a SEQUENCE that are not in the type definition, ignore them"). If these were added to BER, it would score even better on this dimension, although this is not currently planned, and would probably further worsen BER's score on the CPU dimension.
Implementation effort: This dimension relates to the complexity of the encoding rules. PER scores worse than BER on this dimension, and LWER probably considerably better.
Security: There are a number of security-related features that could give rise to requirements for additional encoding rules. Some of them, such as selective field encryption, may even require additions to the notation to identify fields to be encrypted. In early 1992 there were no plans for any security-related encoding rules, other than the work on canonical versions of BER and PER.
Structure in the encoding: This dimension relates to the ability to identify parts of the encoding with parts of the (structured) abstract value, making it possible to provide a receiving application with detailed information on what fields are not what was expected while still providing values for other fields. A high score on this dimension generally goes with a high score on the extensibility dimension, but usually carries penalties on the bandwidth and CPU dimensions. BER is strong on this dimension, and PER and LWER much weaker.
Processing without knowledge: This dimension relates to the ability to carry out a number of processing tasks on a received encoding without knowledge of the ASN.1 type from which it was derived. BER, using only EXPLICIT TAGS scores very highly, enabling a line monitor to display the structure of the encoding, with characters fields as characters, integers as integers, booleans as true and false, and so on. With IMPLICIT tags BER is much weaker, but it is still possible to identify structures and to parse the encoding into primitive elements. Both PER and LWER can do very little with an encoding unless the ASN.1 type is available (and the same as the encoder used). Again, a high score on this dimension tends to correlate with a high score on the extensibility dimension.
To quote from an ISO output document produced in early 1992: "A judicious population of the transfer syntax dimensional framework (... described above ...) will considerably enhance the capability of OSI applications and other specifications using ASN.1 to operate in a range of environments, without causing an undue proliferation of options that could prejudice interworking."
To conclude this chapter, we look at two other notations used to define data structures to be used for computer communications.
The first notation to consider is the EDIFACT graphical notation. EDIFACT (Electronic Data Interchange for Finance, Administration, Commerce, and Transport) is a development of a number of EDI (Electronic Data Interchange) and TDI (Trade Data Interchange) standardization efforts. The work on standards for the transfer of documents related to trade (and particularly to international trade) proceeded in parallel with OSI development, with both groups relatively unaware of what the other group was doing. EDIFACT was produced starting in the late 1970s and through the 1980s by the United Nations Working Party on Facilitation of International Trade Procedures, and is the result of merging earlier work, notably the ANSI X12 Standard and earlier UN work within the UN Economic Commission for Europe, called Guidelines for Trade Data Interchange (TDI). Unfortunately the result at this time has not been to produce a single standard, but rather a third standard, and when the X.400 (electronic mail) Recommendation was extended in 1991 to handle the transmission of EDIFACT documents, it provided an ASN.1 OCTETSTRING to carry encodings of the documents, together with a flag (an OBJECT IDENTIFIER) saying whether it was the ANSI X12 version, or the TDI version, or the EDIFACT version that was being carried.
Some parts (but by no means all) of the documentation of EDIFACT have been submitted to ISO and is an ISO standard. In particular, the encoding rules for EDIFACT documents are ISO 9735. The encodings use text characters throughout, and were originally designed to enable EDIFACT documents to be transferred over the telex system.
The interesting part of EDIFACT for the purposes of this chapter is the notation for defining message structures at the abstract level. This is the graphical syntax of EDIFACT. figure 8.19: Edifact graphical syntax shows an example of a simple datastructure defined using the EDIFACT notation, and figure 8.20: Equivalent ASN.1 shows the equivalent ASN.1 type definition. Some work has been done comparing the power of this notation with ASN.1, and it is clear that a formal mapping could be defined from the EDIFACT graphical syntax to ASN.1 (but not the reverse - ASN.1 is more powerful). Those who are not computer programmers generally find the EDIFACT graphical notation more usable than ASN.1, and it remains the case for the present and perhaps foreseeable future (in the early 1990s) that EDIFACT will remain as an abstract syntax notation and encoding rules for transfer syntax alongside ASN.1. Its use is likely to be (as the name implies) largely restricted to the definition of trade-related documents and perhaps personnel record systems, rather than for general-purpose application layer protocols. It would not be totally unreasonable to equate ASN.1 with Fortran and EDIFACT with COBOL.
The second notation that is worth a brief mention is the RPC (Remote Procedure Call) Interface Definition Notation (IDN). The RPC standard (and its relationship to ROSE) is discussed in more detail later, but its main technical content is the definition of a language for defining the parameters of a procedure call, and the results it returns. Thus it is directly replacing the use of ASN.1 with the ROSE OPERATION and ERROR macros. The aim in the IDN was to produce a notation which was somewhat closer to the datatype definition syntax of traditional programming languages, with the explicit intent of trying to get programming language standards to write in support for the IDN. After some discussion, ASN.1 was rejected as too communication-oriented to be acceptable in this role. Having said that, at least one provider of ASN.1 tools has now produced a C compiler and run-time system that directly accepts ASN.1 as a means of defining datastructures that can be accessed by C language statements. The IDN standard does not define its own transfer syntaxes. Rather it defines a formal mapping from use of the IDN notation into an ASN.1 datatype, allowing the ASN.1 encoding rules then to be applied (and the ASN.1 types to be carried in ROSE messages). Thus RPC can be seen primarily as providing a more programming-language-friendly interface to ASN.1 and ROSE.
Go to contents Go to Salford home page